
Rilasci non-funzionali
10 Dec 2022 - Giulio Vian - ~10 minuti
Cosa sono i rilasci non-funzionali? È presto detto: sono rilasci “tecnici” senza alcun cambiamento funzionale. Qualcuno si chiederà che senso abbia un rilascio senza modifiche al codice. Facile, non cambia il codice ma qualcosa al contorno che non è rilasciabile separatamente. Il caso più comune oramai è dover aggiornare una libreria vulnerabile con una versione più sicura, reimpacchettare e rilasciare di nuovo. Purtroppo negli ultimi anni il ritmo di questi cambiamenti è mutato drasticamente ed impatta noi e le nostre applicazioni!
AVVISO: questo articolo è più lungo del solito, supera le 2000 parole, e potrebbe richiedere 15-20 minuti per leggerlo integralmente.
Frequenza di rilascio altrui
Non molto tempo fa il ritmo del cambiamento nell’industria del software era tranquillo. Ogni 3 anni circa usciva una nuova versione del sistema operativo o del database. La cadenza per gli strumenti di sviluppo era circa il doppio, circa 18 mesi, ma si aveva comunque tutto il tempo per prepararsi e adattarsi. Successivamente si è iniziato a vedere un aumento nella frequenza delle patch e pure pacchetti di patch contenenti nuove funzionalità (ad esempio Visual Studio 2010 Service Pack 1 ). Questa cadenza è cambiata drasticamente nell’ultimo lustro: il ritmo delle patch è aumentato notevolmente, non solo per le versioni minori ma persino quelle maggiori. Di conseguenza, i team devono affrontare ora cambiamenti quotidiani nelle loro dipendenze, soprattutto se si considera quante librerie compongono un’applicazione moderna. Il flusso delle modifiche tocca anche il sistema operativo, le piattaforme applicative (runtime), i database, le API di servizi di terze parti e i componenti preconfezionati sotto forma di immagini Docker.
Vediamo alcune statistiche che spero vi convinceranno.
Aggiornamenti delle piattaforme
Se esaminiamo la cadenza di rilascio di alcune delle principali piattaforme di sviluppo, sembra che non ci sia molta fretta di far uscire nuove versioni.
| Piattaforma | Cadenza rilasci LTS | Rilasci minori(STS) | Frequenza dellepatch (media) | Versione usata come riferimento | Fonte |
|---|---|---|---|---|---|
| Google Chrome | 1 mese | n.d. | 14 giorni | n.d. | https://blog.chromium.org/2021/03/speeding-up-release-cycle.html |
| Go | 6 mesi† | n.d. | 26 giorni | 1.16 | https://github.com/golang/go/wiki/Go-Release-Cycle |
| Node.JS | 30 mesi | 6 mesi | 25 giorni | v14 | https://nodejs.org/en/about/releases/ |
| MongoDB | 1 anno | 3 mesi | 5 settimane | 5.0 | https://docs.mongodb.com/manual/reference/versioning/ |
| Java | 2 anni | 6 mesi | 12 settimane | JDK 11 | https://www.oracle.com/java/technologies/java-se-support-roadmap.html |
| .NET | 3 anni | 18 mesi | 6 settimane | Core 3.1 | https://dotnet.microsoft.com/en-us/platform/support/policy/dotnet-core |
† Go supporta le due versioni maggiori più recenti.
La chiara eccezione è qui Chrome (e altri browser basati su Chromium come Edge o Brave). Se fosse questo l’unico oggetto con una cadenza mensile, massì può essere fastidioso verificare che il codice JavaScript continui a funzionare e aggiornare componenti legati alla versione del browser come il Selenium Web Driver, però nulla di drammatico.
Questa percezione cambia, se esaminiamo la frequenza media di aggiornamento ovvero le patch. Scopriamo che gli aggiornamenti avvengono molto più spesso, ogni poche settimane. Questi aggiornamenti includono correzioni di bug e, cosa più importante, risolvono bug di sicurezza. L’applicazione di patch a qualsiasi runtime utilizzato da un’applicazione è un dovere morale per qualsiasi sviluppatore professionista in modo da proteggere l’organizzazione dagli attacchi. Fortunatamente, in molti casi, il runtime viene installato separatamente in modo che il funzionamento IT possa mantenerlo autonomamente sollevando i programmatori da tale responsabilità.
In ogni caso è evidente che un team medio avrà bisogno di aggiornare la propria piattaforma di sviluppo almeno una volta al mese.
Aggiornamenti dei Sistemi Operativi
Analizzando fonti come le immagini ufficiali Docker osserviamo un fenomeno simile: benché il ritmo dei principali rilasci sia, generalmente, pluriennale, la disponibilità di aggiornamenti (patch) si presenta ogni tre o quattro settimane.
| Sistema Operativo | Cadenza rilasci LTS | Rilasci minori(STS) | Frequenza dellepatch (media) |
|---|---|---|---|
| Alpine | 6 mesi | 52.2 giorni (7.5 settimane) | |
| Ubuntu | 2 anni | 6 mesi | 21.8 giorni |
| Amazon Linux | 2 anni | 3 mesi | 21.7 giorni |
| Windows Server | 3 anni | 6 mesi | Martedì delle Patch ogni mese |
Sia che usiate macchine virtuali che containers dovrete preoccuparvi di rinfrescare il sistema operativo con gli aggiornamenti di sicurezza, tipicamente ogni 3-4 settimane.
Dipendenza dalle librerie terze-parti
L’uso di librerie terze parti è in costante crescita nel costruire soluzioni, come si vede in questo grafico da Sonatype 2021 State of the Software Supply Chain report.

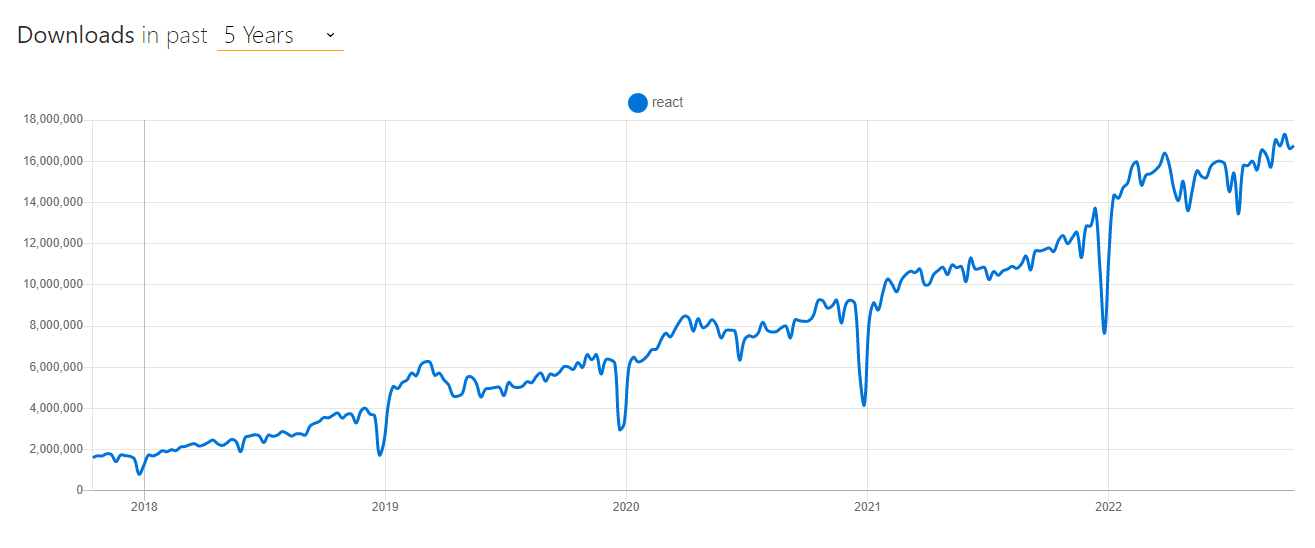
Questo dato generale è confermato dalle statistiche dei download per librerie ampiamente utilizzate come React. React cresce di 8 volte in meno di 5 anni!
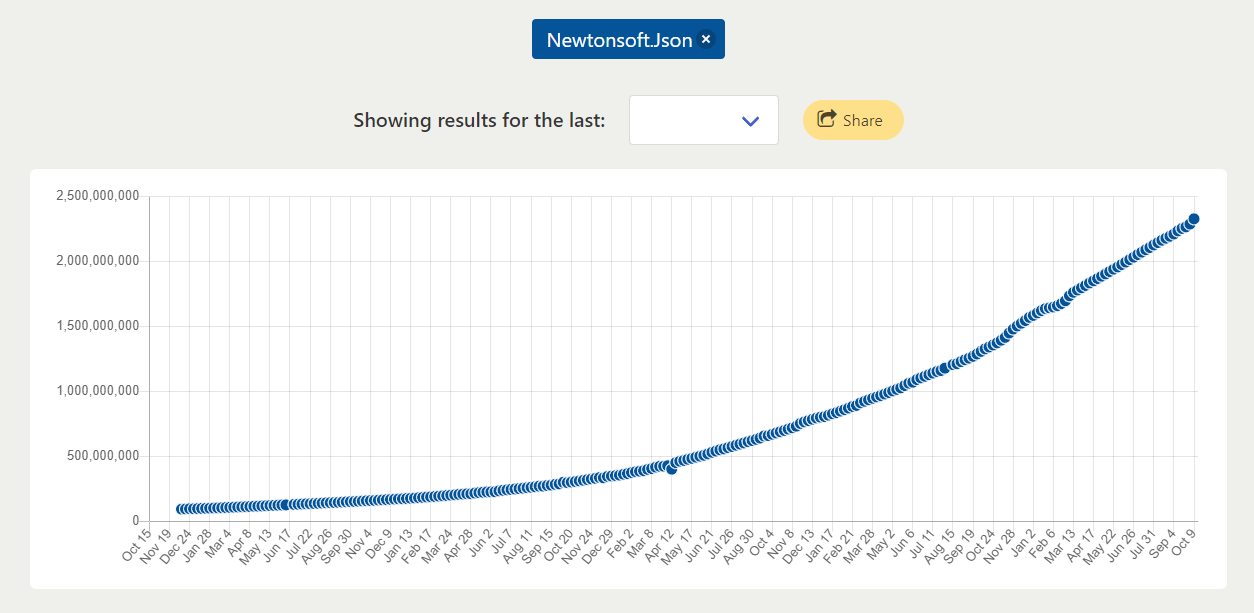
Similmente per Newtonsoft.Json, una famosa libreria .NET: aumentata di 24 volte.
Le applicazioni moderne usano sempre più librerie ma quanto?
Son riuscito a trovare un paio di studi al riguardo.
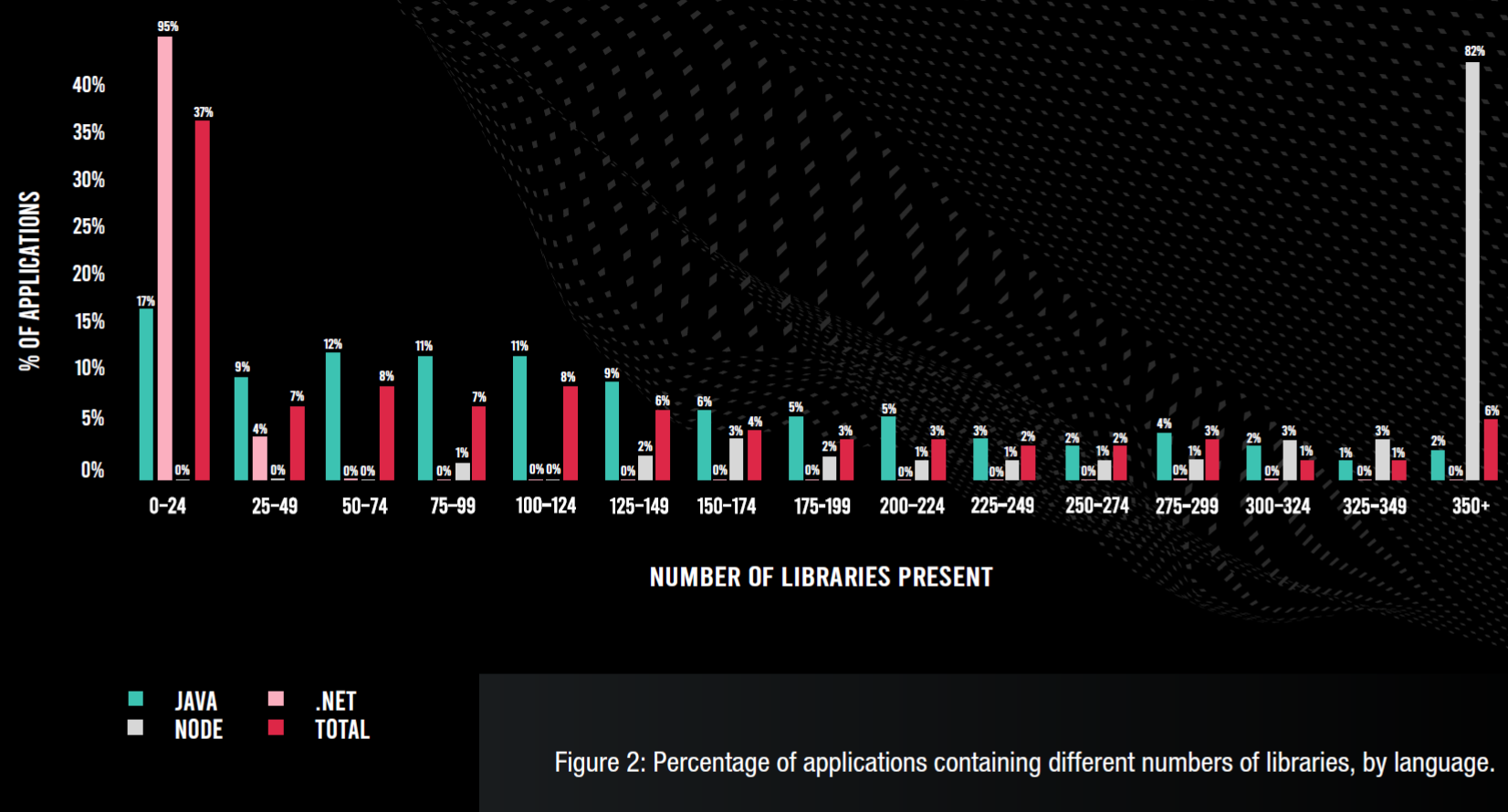
Il primo è di Contrast-Labs
2021 Open-Source Security Report
che mostra come linguaggi diversi dipendano in modo diverso dalle librerie open-source.
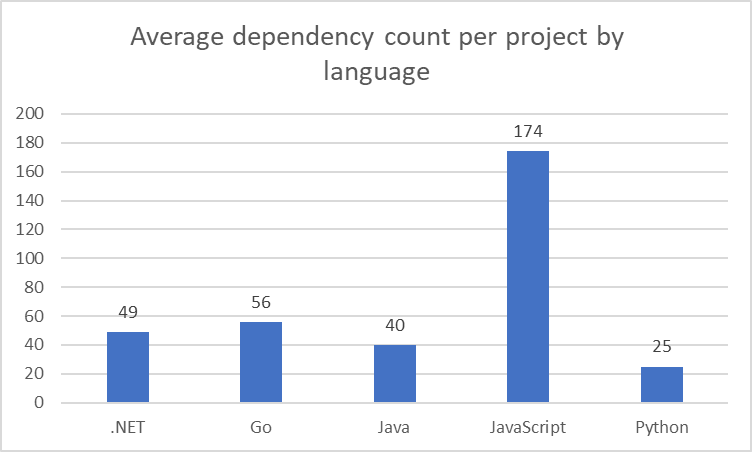
Source: 2022 Snyk user data.
Insomma è certo che le applicazioni moderne dipendono da diecine se non centinaia di librerie terze parti.
Aggiornamenti delle librerie terze-parti
Purtroppo gli studi sulle librerie di terze-parti si focalizzano su aspetti particolari e non son stato in grado di reperire dei dati aggregati sugli aggiornamenti, e allora ho provato ad esaminare singoli casi, relativi a componenti di uso comune.
- log4j-core è stato aggiornato in media ogni 72 giorni (10,3 settimane)
- spring ogni 89 giorni (12,7 settimane)
- Newtonsoft.Json 137.1 giorni (19.6 settimane)
Intuitivamente se impiego dieci librerie e ciascuna viene aggiornata ogni dieci settimane, ogni settimana almeno avrà una nuova versione. Un conferma indiretta ci viene da strumenti come Dependabot : chi li usa si sarà sicuramente accorto che ogni settimana, se non ogni giorno, qualcuna delle librerie nel progetto ha una nuova versione.
Quanti di questi aggiornamenti sono necessari e quanti si possono postporre? Certamente non si possono rimandare quando riguardano la sicurezza. Più è ampio il mio parco applicativo, più grosse sono le mie applicazioni, ed ecco che distinguere tra aggiornamenti di sicurezza e non diventa un compito improbo se non inutile. Il problema di cosa aggiornare si sposta su un piano diverso, che vedremo nella prossima sezione.
Cosa significa in termini DevOps
Una applicazione moderna dipenderà da tutti e tre i fattori sopra menzionati: sistema operativo, piattaforma run-time e librerie di terze parti. Nell’insieme i tre concorrono a farci aggiornare i sistemi anche in assenza di modifiche funzionali.
Chi aggiorna cosa
L’architettura di deploy dell’applicazione detterà la concreta modalità di aggiornamento (vedi figura).
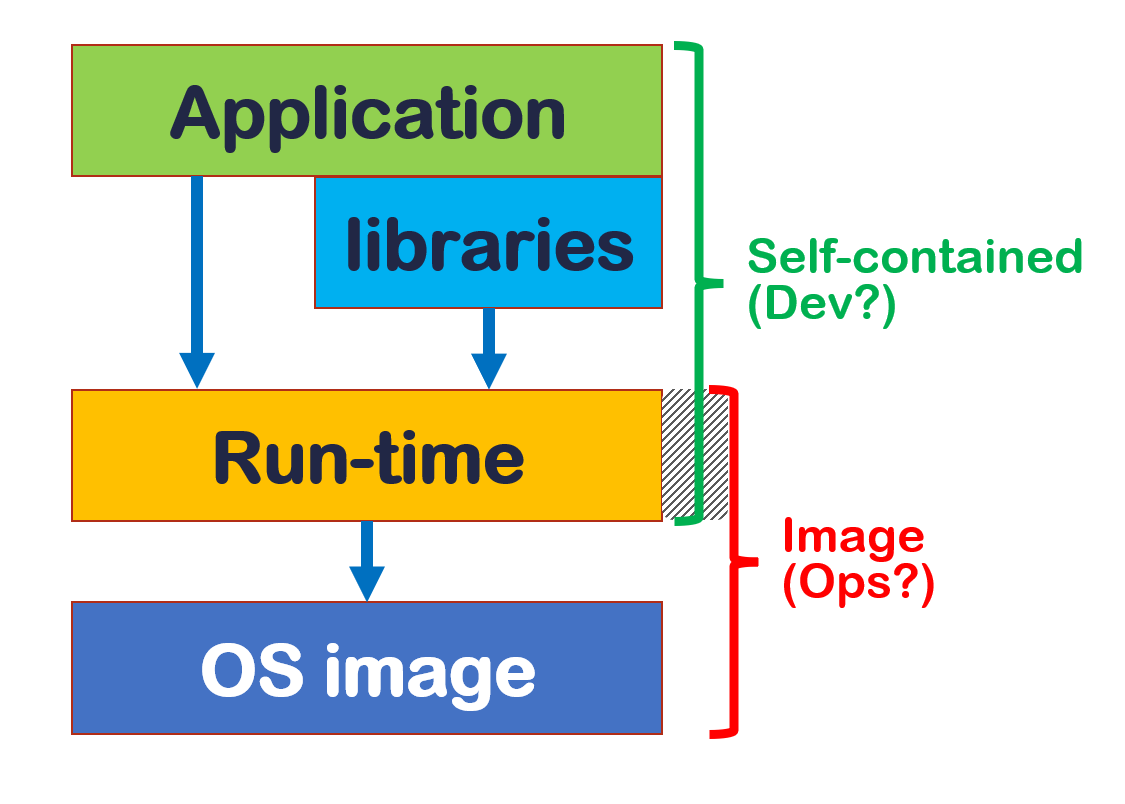
Ci sono due scenari principali. Se si adotta il principio dell’infrastruttura immutabile (Immutable infrastructure), qualsiasi elemento richieda un aggiornamento, implicherà il rilascio dell’intera pila, dal sistema operativo all’applicazione. In caso contrario la responsabilità si ripartisce tra gruppo di sviluppo, sistemisti e fornitore della piattaforma. Ad un estremo abbiamo architetture serverless, come AWS Lambda o Azure Function, che gestiscono anche il run-time oltre al sistema operativo: dovremo preoccuparci solamente degli aggiornamenti di librerie. All’altro estremo abbiamo applicazioni “self-contained” su macchine virtuali: il pacchetto di distribuzione contiene il run-time, mentre le IT operation si preoccupano di aggiornare il sistema operativo. L’aggiornamento delle librerie richiede sempre e comunque ricompilare e reimpacchettare l’applicazione.
Aggiornare con serenità
Indipendentemente da quanti strati tocchiamo in un rilascio, resta il problema di come garantire che un qualsiasi aggiornamento non rompa l’applicazione.
L’ovvia risposta è avere dei test, ma questi devono sottostare ad una particolare ottica. La tipica preoccupazione di un team di sviluppo è automatizzare test di tipo funzionale bilanciandosi tra varie categorie di test: unit test, integration tests e UI test (la famosa piramide dei test di Mike Cohn ). Ma nello scenario di un ambiente che cambia, librerie che cambiano, è importante avere una batteria di test che coprano aspetti non funzionali. Cosa sono questi test non-funzionali? Il mio vecchio libro di Software Engineering già ne elencava parecchi: affidabilità, robustezza, performance, usabilità, manutenibilità, riusabilità, portabilità, comprensibilità e interoperabilità. Un fracco di roba! e dovremmo stupirci che questo elenco sia valido dopo tutti questi anni!
Ragioniamo allora, da quali rischi vogliamo garantirci? In primis da cambiamenti nel comportamento degli strati sottostanti, ma, dato che è impensabile scrivere test per tutte le possibili API che usiamo, riduciamo ancora lo scopo. La nostra batteria di test deve coprire quelle interazioni con l’ambiente più sensibili a restrizioni di sicurezza o che si riflettono maggiormente sui percorsi critici del sistema. In altre parole una test harness ossia mettere le briglie all’applicazione per domarla. L’individuazione di questi percorsi critici richiederebbe un lungo trattamento, in questa sede raccomanderei di concentrarsi su restrizioni di sicurezza: apertura di file, di sockets, accesso a chiavi private, algoritmi di cifratura.
Continuous Update
πάντα ῥεῖ diceva un tale e così noi dobbiamo adattarci a questo continuo flusso di cambiamenti e ricostruire continuamente applicazioni, immagini e ambienti operativi. In che modo?
Il più semplice ma di limitata applicabilità è di ricostruire tutto ogni notte, accogliendo tutti gli aggiornamenti e prendendo le ultime versioni di librerie: il rischio è relativo perché coperti dai test. Più grosso il sistema, più l’operazione diviene costosa e lenta. Ad un certo punto si è costretti ad ottimizzare il processo. Vediamo come potrebbe essere un processo ideale.
Abbiamo due flussi di aggiornamenti: nuove versioni che richiedono ricompilazione (librerie, immagini base docker, immagini di VM) e patch direttamente applicabili su binari.
Per il primo flusso è necessario risalire dall’elemento aggiornato (e.s. Log4J v2.17.1) alle applicazioni che ne fanno uso, e per queste dove stanno i sorgenti e le pipeline per ricompilare e redistribuire.
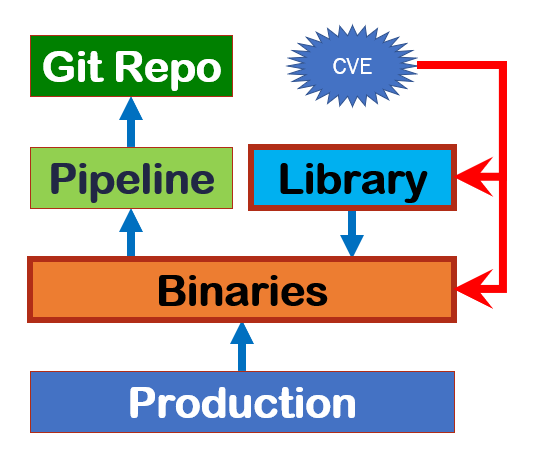
In queste situazioni diventa chiaro che dobbiamo avere dei processi e convenzioni ben chiare ben oltre la “banale automazione DevOps”. Gli ulteriori elementi necessari a gestire la complessità sono diversi. Per quanto riguarda la gestione dei sorgenti necessitiamo di:
- una funzione di ricerca potente e veloce per trovare ogni riferimento a librerie, versioni, sistemi operativi;
- una distinzione chiara di quali repository contengono codice di produzione e quali no e perciò ignorabili;
- una convenzione o notazione che indichi quale ramo contiene la versione di produzione nei suddetti repository.
Tutte queste cose sono disponibili nei sistemi moderni o realizzabili con un costo assai modesto.
In secondo luogo bisogna attrezzarsi per modifiche a tappeto, per esser capaci di modificare tutti i riferimenti ad una versione di libreria o di sistema operativo. Se la massa totale di sorgenti è limitata, qualche GB, basta clonare tutti i repository, editare con sed e magari awk e riportare le modifiche nell’opportuno ramo condiviso.
Non ho conoscenza di strumenti pensati per modifiche trasversali in un portafoglio di repo sorgenti: se li avete trovati, fatemi sapere.
Oltre ai sorgenti anche le pipeline devono soddisfare alcuni criteri, ovvero:
- sappiamo quali pipeline generano oggetti per la produzione, ossia è facile scartare pipeline di prova, esperimenti ecc.;
- dato un certo oggetto conosciamo la pipeline che lo ha prodotto e può rigenerarlo (in altre parole la SBOM, Software Bill of Materials, distinta base del software);
- l’infrastruttura di build è in grado di scalare sufficientemente anche in caso di rilascio massiccio, con l’accodamento di diecine e centinaia di build contemporaneamente;
- il meccanismo approvativo, la promozione in produzione, è in grado di scalare in caso di rilascio massiccio.
Quest’ultimo punto merita un approfondimento riguardo le approvazioni. Tipicamente le approvazioni sono collegate ad una pipeline e all’ambiente target dove avverrà il rilascio. Con un rilascio massiccio, della maggior parte del portafoglio applicativo, si produce una tempesta di approvazioni non facile da gestire con gli strumenti esistenti. Al punto che potrebbe essere più semplice impostare delle pipeline alternative per il caso di rilascio massiccio per non trovarsi a rincorrere 50 diversi personaggi per l’approvazione in emergenza. Sarà interessante vedere come le piattaforme di CI/CD evolveranno per comprendere tali casistiche.
Conclusioni
Ritengo di aver portato sufficienti argomenti alla causa dei rilasci non-funzionali: trascurare gli aggiornamenti a qualsiasi livello aumenta solo i rischi di sicurezza. Purtroppo o per fortuna le attività di aggiornamento non sono più limitate all’ambito sistemistico, ma coinvolgono abitualmente anche lo sviluppo. Restano aperte le domande sul quanto e sul come.
Per alcuni il problema è di facile soluzione, avendo poche applicazioni su una singola piattaforma e strumenti come
npm audit
o
dependabot
. Per altri la situazione è complessa e variegata, mancando di strumenti adeguati per la scala delle attività.
Fondamentale che non ci lasciamo cogliere di sorpresa ed invece ci muoviamo nella direzione di una soluzione.