
Non-functional Releases
10 Dec 2022 - Giulio Vian
What are non-functional releases? It is easy to say: they are “technical” releases with no functional changes. Someone will ask why re-releasing the same thing with no code changes. It makes sense when you do not change functional code but something around it, something that cannot be released separately. The most common case now happens one must replace a vulnerable library with a more secure version, then repackage and release again. Unfortunately in recent years the pace of these kind of changes has changed dramatically and impacts us and our applications!
NOTICE: This article is longer than usual, over 2000 words, and may take 15-20 minutes to read in full.
Release frequency in the past
Not long ago the pace of change in the software industry was quiet. Every 3 years or so a new version of the operating system or database came out. The cadence for the dev tools was faster, about 18 months, but you still had plenty of time to prepare and adjust. Later we started to see an increase in patch frequency as well as patch packs containing new features (an example was Visual Studio 2010 Service Pack 1 ). This cadence has shortened drastically in the last five years: the pace of patches has increased significantly, not only for minor releases but also for major ones. As a result, teams now face daily changes in their dependencies, especially when you consider how many libraries make up a modern application. The flow of changes also affects the operating system, application platforms (runtimes), databases, APIs of third-party services and components pre-packaged in the form of Docker images.
Let’s see some statistics that, hopefully, will convince you.
Platform Updates
If we look at the release cadence of some of the major development platforms, there seems to be not much of a rush to bring out new releases.
| Platform | LTS release cadence | Minor Releases(STS) | Frequency ofpatch (average) | Version used as reference | Source |
|---|---|---|---|---|---|
| Google Chrome | 1 month | n.a. | 14 days | n.a. | https://blog.chromium.org/2021/03/speeding-up-release-cycle.html |
| Go | 6 mesi† | n.a. | 26 days | 1.16 | https://github.com/golang/go/wiki/Go-Release-Cycle |
| Node.JS | 30 months | 6 months | 25 days | v14 | https://nodejs.org/en/about/releases/ |
| MongoDB | 1 year | 3 months | 5 weeks | 5.0 | https://docs.mongodb.com/manual/reference/versioning/ |
| Java | 2 years | 6 months | 12 weeks | JDK 11 | https://www.oracle.com/java/technologies/java-se-support-roadmap.html |
| .NET | 3 years | 18 months | 6 weeks | Core 3.1 | https://dotnet.microsoft.com/en-us/platform/support/policy/dotnet-core |
† Go supports the two most recent major releases.
The clear exception here is Chrome (and so other Chromium-based browsers like Edge or Brave). If this were the only item with a monthly cadence, it would be a minor annoyance to verify that the JavaScript code continues to work and update components related to the browser version such as the Selenium Web Driver.
This perception changes if we look at the average update rate or patches rate. We find that updates happen much more often, every few weeks. These updates include bug fixes and ,most importantly, fix security bugs. Patching all runtimes used by an application is a moral duty for any professional developer in order to protect the organization from attack. Fortunately, in many cases, the runtime is installed separately so that IT operation can maintain it themselves and relieve the burden from developers.
In any case it is clear that an average team should update their development platform at least once a month.
Operating System Updates
Analyzing sources such as the official Docker images we observe a similar phenomenon: although the pace of major releases is generally two or three years, the availability of updates (patches) occurs every three to four weeks.
| Operating System | LTS release cadence | Minor Releases (STS) | Frequency of patches (average) |
|---|---|---|---|
| Alpine | 6 months | 52.2 days (7.5 settweeksimane) | |
| Ubuntu | 2 years | 6 months | 21.8 days |
| Amazon Linux | 2 years | 3 months | 21.7 days |
| Windows Server | 3 years | 6 months | Patch Tuesdays every month |
Whether you use virtual machines or containers you must worry about refreshing the operating system with security updates, typically every 3-4 weeks.
Depending on third-party libraries
The use of third-party libraries is steadily growing in building solutions, as seen in this chart from Sonatype 2021 State of the Software Supply Chain report.
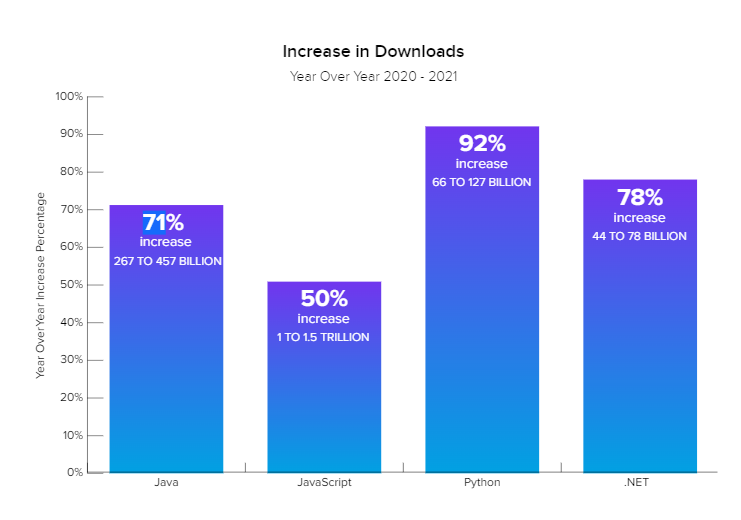
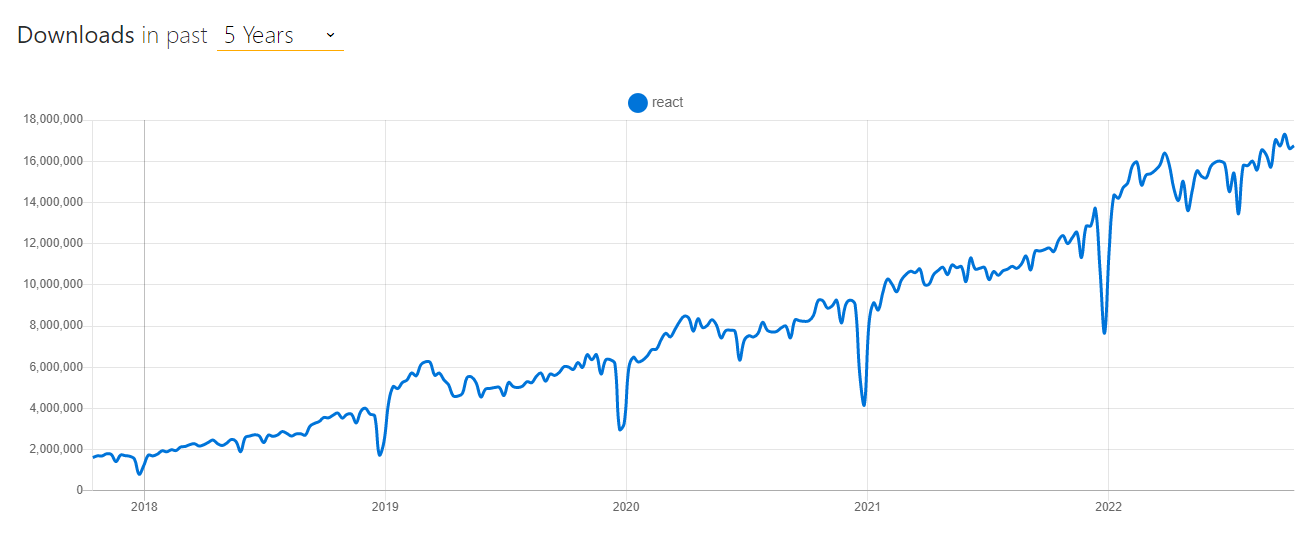
This general figure is confirmed by the download statistics for widely used libraries such as React. React grows 8x in less than 5 years!
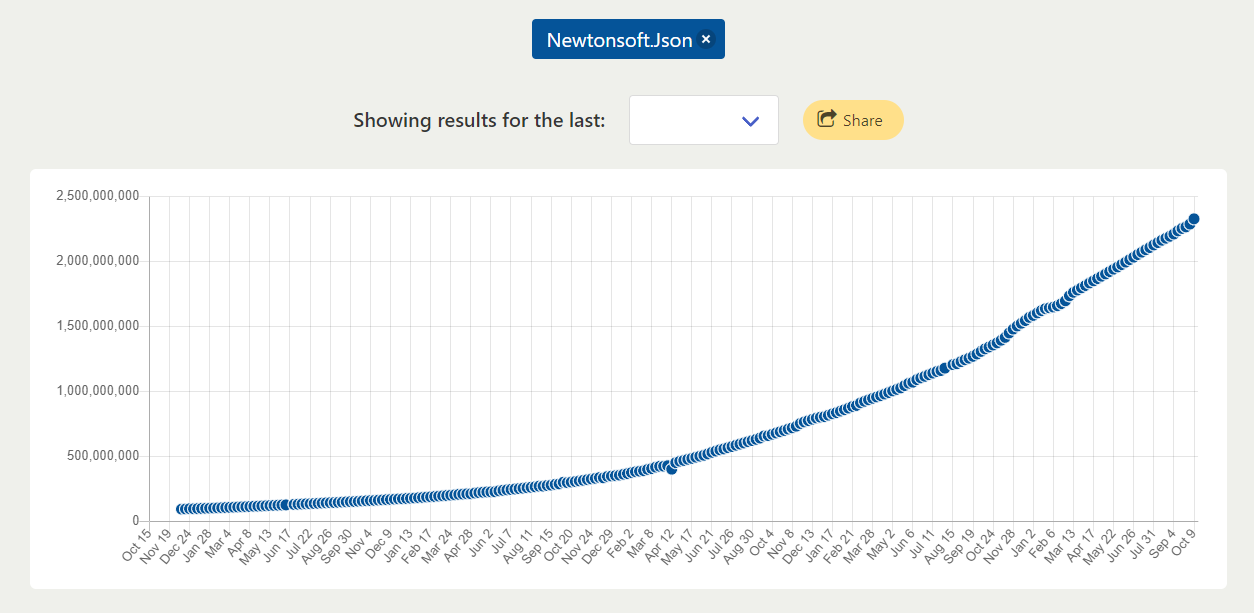
Similarly for Newtonsoft.Json, a famous .NET library: increased by 24 times.
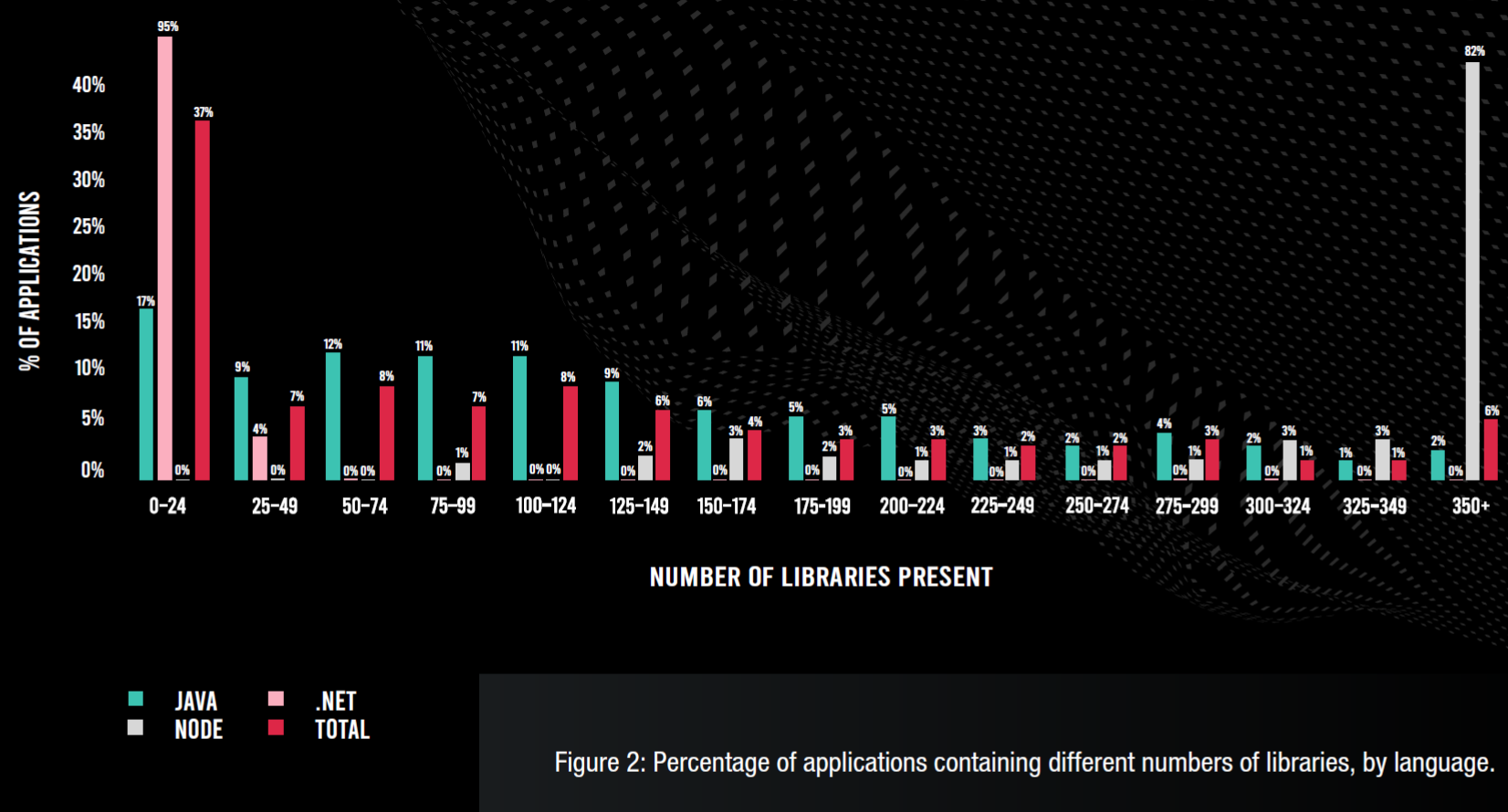
Modern applications use more and more libraries but how much?
I managed to find a couple of studies on this.
The first is from Contrast-Labs
2021 Open-Source Security Report
which shows how different languages varies in their use of open source libraries.
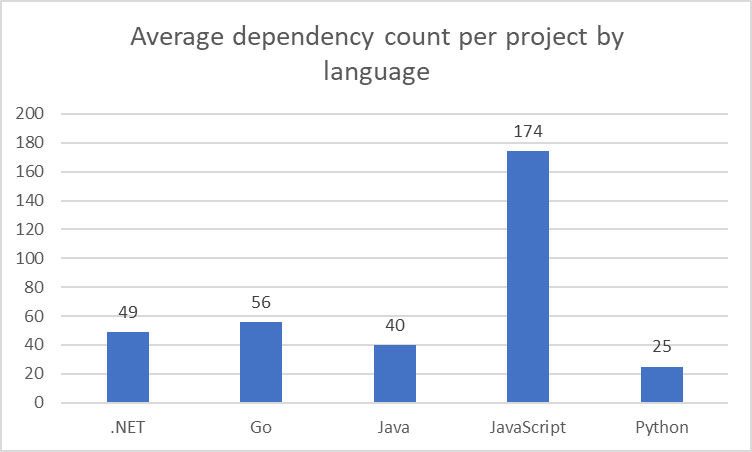
Source: 2022 Snyk user data.
In short, it is certain that modern applications depend on tens if not hundreds of third-party libraries.
Third-party library updates
Unfortunately, studies on third-party libraries focus on particular aspects and I haven’t been able to find aggregate data on updates, so I tried to examine single cases, of commonly used components.
- log4j-core was updated every 72 days (10.3 weeks) on average
- spring every 89 days (12.7 weeks)
- Newtonsoft.Json 137.1 days (19.6 weeks)
Intuitively, if I use ten libraries and each is updated every ten weeks, at least every week will have a new version. An indirect confirmation comes from tools like Dependabot : those who use them will surely have noticed that every week, if not every day, some of the libraries in the project have a new version.
How many of these updates are needed and how many can be deferred? Certainly they cannot be postponed when they concern security. The larger my application portfolio and the bigger are my applications, the harder it becomes to distinguishing between security and non-security updates, and maybe not only a difficult task but useless. The problem of determining what to update is a game on its own, and I will spend the next section dissecting it.
What it means in DevOps terms
A modern application depends on the three factors mentioned above: operating system, run-time platform, and third-party libraries. Together they contribute in forcing us to update the systems even in the absence of functional changes.
Who updates what
The deployment architecture of the application dictates the way we actually update (see figure).
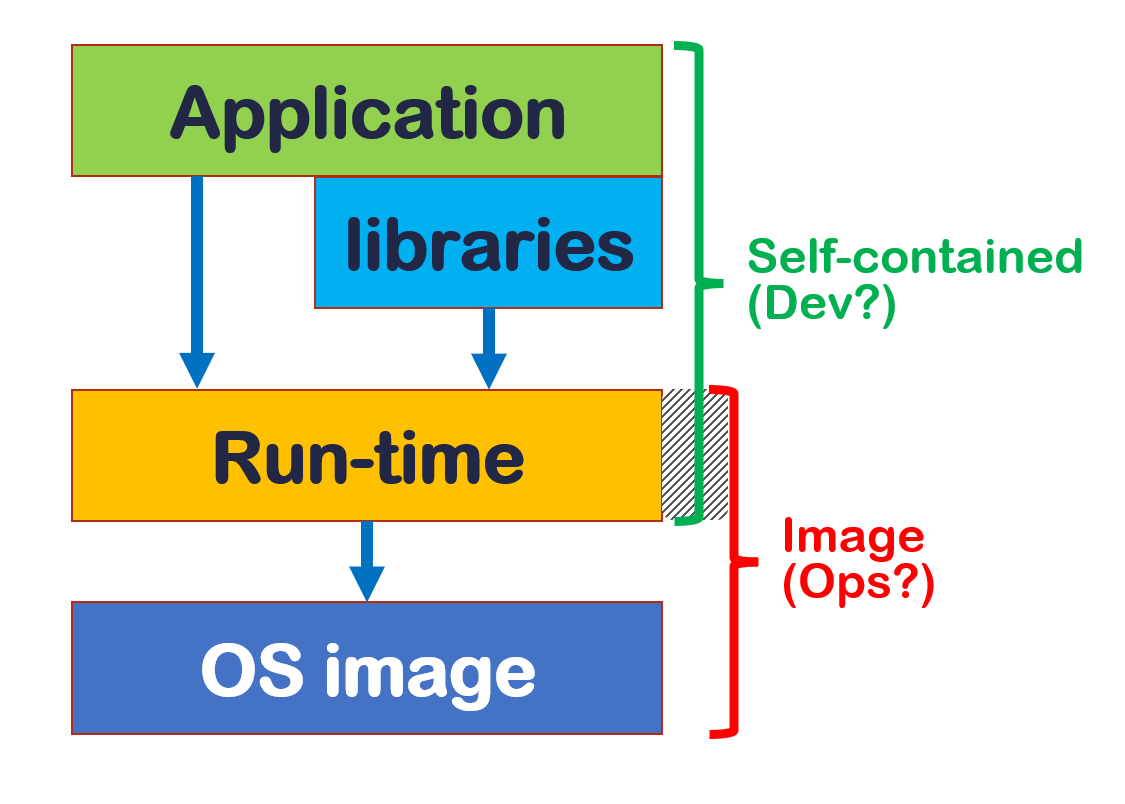
There are two main scenarios. If you adopt the principle of immutable infrastructure, anything that requires an update involves releasing the entire stack, from the operating system to the application. If you don’t (mutable infrastructure), the responsibility is divided between development groups, systems engineers and platform suppliers. At one extreme we have serverless architectures, such as AWS Lambda or Azure Functions, whose provider manages both the run-time and the operating system: we have to worry about library updates only. At the other extreme we have “self-contained” applications on virtual machines: the distribution package contains the run-time, while IT operations take care of updating the operating system. In any case, updating the libraries always requires recompiling and repackaging the application.
Update with peace of mind
No matter how many layers we touch in a release, we still face the problem how to ensure that no update breaks the application.
The simple and obvious answer is to have tests, except that the test must be made with a specific goal in mind. The typical concern of a development team is to automate functional tests with a balance between unit tests, integration tests and UI tests (the famous [Mike Cohn’s test pyramid](https://www.mountaingoatsoftware.com/blog/ the-forgotten-layer-of-the-test-automation-pyramid)). In the scenario of a constantly changing environment, it’s important to have a battery of tests that cover non-functional aspects. What are these non-functional tests? My university Software Engineering book listed several non-functional software properties: reliability, robustness, performance, usability, maintainability , reusability, portability, comprehensibility and interoperability. A bunch of stuff! And they aren’t changed much after so many years!
Let’s think which risks do we want to insure ourselves from? Primarily by changes in the behavior of the underlying layers, but, since it’s unthinkable to write tests for all possible APIs used by an application, we should narrow the scope. Our test battery must cover those interactions with the environment that are most sensitive to security restrictions or that have a greater impact on critical system paths. In other words, a test harness i.e. putting the bridle on the application to tame it. Identifying such critical paths would require a long discussion, for now I recommend focusing on security restrictions: opening files, opening sockets, accessing private keys, encryption algorithms.
Continuous Update
πάντα ῥεῖ said someone and so we have to adapt to this continuous flow of changes and continuously rebuild applications, images and operating environments. But how?
The simplest way is to rebuild everything every night, accepting all the updates and taking the latest library versions. The risk is relative because it is covered by the tests but its applicability is limited. The bigger the system, the more expensive and slow the operation becomes. At some point one is forced to optimize the process. Let’s see what an ideal process might look like.
We have two streams of updates: new releases that require recompiling (libraries, docker base images, VM images) and directly applicable patches on binaries.
The first flow goes back from the updated element (e.g. Log4J v2.17.1) to the applications that use it, and for these applications where the sources and pipelines for recompiling and redistribution are.
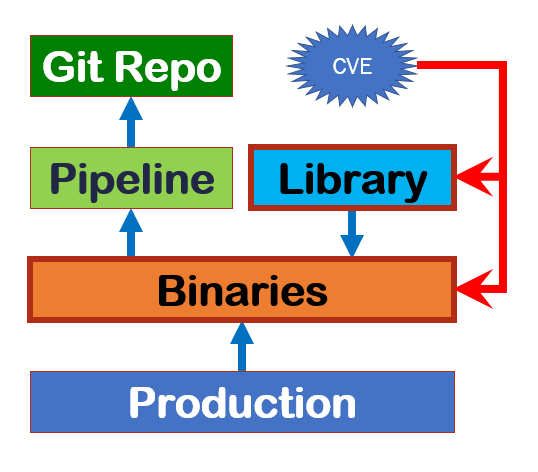
In these situations it becomes clear that we need to have clear processes and conventions well beyond the “mundane DevOps automation”. The additional elements necessary to manage the complexity are different. As far as source management is concerned, we need:
- a powerful and fast search function to find any reference to libraries, versions, operating systems;
- a clear distinction of which repositories contain production code and which do not and therefore skippable;
- a convention or notation indicating which branch contains the production version in the above repositories.
All of these things are either available in modern systems or achievable for very little cost.
For the second flow, you need to equip yourself for sweeping changes, being able to change all the references to a library or operating system version. If the total size of source code is limited, a few GB, just clone all the repositories, edit with sed and maybe awk and put the changes back in the appropriate shared branch.
I’m not aware of any tools meant for cross editing in a source repo portfolio - if you’ve found them, let me know.
In addition to the sources, the pipelines must also meet some criteria, namely:
- we know which pipelines generate objects for production, i.e. it is easy to discard test pipelines, experiments, etc.;
- given a certain object, we know the pipeline that produced it and can regenerate it (in other words, the SBOM, Software Bill of Materials, bill of material of the software);
- the build infrastructure is able to scale sufficiently even in case of a massive release, with dozens and hundreds of builds being queued at the same time;
- the approval mechanism, the promotion in production, is able to scale in case of mass release.
This last point deserves further consideration. Typically approvals are bound to a pipeline and to a target environment where the release will be deployed. A massive release of most of the application portfolio produces a storm of approvals that is not easy to manage in many existing tools. To the point that it might be easier to set up alternative pipelines for the case of mass release so as not to find yourself chasing 50 different characters for emergency approval. It will be interesting to see how CI/CD platforms evolve to encompass such cases.
Conclusions
I think I made enough arguments for non-functional releases: neglecting updates at any level only increases the security risk. Fortunately or maybe not, updating activities are no longer limited to the system environment: they typically involve development nowadays. Question remain open about how much and how to involve.
For some people, the problem is easy to solve: they have a few applications on a single platform and are supported by tools like
npm audit
or [dependabot] (https://github.com/dependabot). For other folks, the situation is complex and varied, lacking adequate tools for the scale of the activities.
It is essential that we do not allow ourselves to be taken by surprise and instead go in the direction of a solution.