Third upgrade in a row
18 May 2014 - Giulio Vian - ~3 Minutes
Last week I upgraded our TFS infrastructure from 2013 to 2013 Update 2. It was the third upgrade since I started working in this company, which means 3 upgrades in 4 months! This says something about our Development Directors which want the latest features because they need them; it is also a consequence of Product Group’s innovation pace. Call me lucky.
The DevOps movement keeps repeating: the harder to deploy, the more often you have to do it. We are applying this principle in a somewhat original direction, trying to keep the versions of products in our internal IT, as fresh as reasonably possible. At least, my users cannot envy for long teams using Visual Studio Online 
I streamlined the upgrade process around two major phases (rounds) and three minor. The first round upgrades our Staging environment; the second one upgrades the Production TFS environment. The minor phases of each round are: upgrade the TFS Farm, then the Proxy servers, finally the Build and Test infrastructure. In practice I see overlapping that a new cycle start well before the previous finish: we still have many Build controllers at version 2012.2.
Our Staging environment is a close clone of production; it is based on the same architecture (one primary site and one disaster recovery site) and the same databases, which I restore from production backup before testing the upgrade. This configuration helps us validate the process in some respects:
- how much Transaction Log space we need?
- will our customizations cause problems?
- how long it will take to upgrade?
- my scripts have bugs?
Our disaster recovery strategy is based on SQL 2012 AlwaysOn, which means that our TFS databases belongs to the one and same availability group. Since TFS 2012.2 the Upgrade wizard natively supports this configuration, which means you can let the availability group untouched during upgrade. Upgrade changes to the schema and data flow naturally from primary to secondary without intervention. This is good as you do not have to alter SQL configuration during the upgrade process; previously you had to rebuild the availability group, which take several hours when databases are in the hundred-GB size range.
What I would like to see is a way to avoid the service interruption we face today and run the upgrade during normal working hours. Our maintenance window is limited to weekend, as you can see from the diagram.
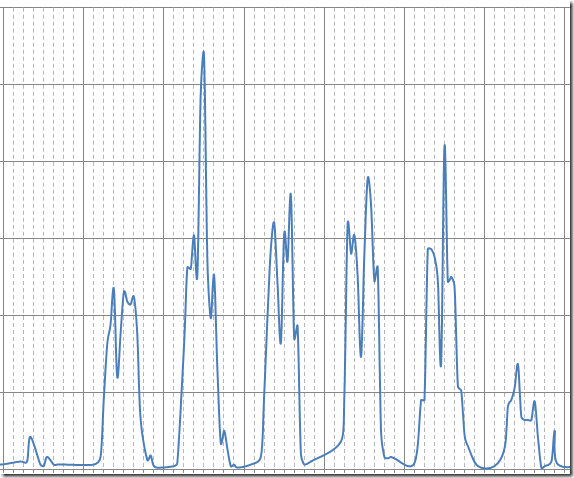
As rollback strategy, that is our line of defense against upgrade failures, is based on VM snapshots and SQL backups.
Finally, here is my checklist for the upgrade
- backup databases
- disable jobs that may interfere with the process, like backups
- quiesce TFS
- remove servers from monitoring (they may need a reboot)
- snapshot all VMs
- restart servers if there are any pending reboot
- mount TFS ISO image on all AT nodes
- start transaction log monitoring script
- install update (bits) i.e. run tfs_server.exe on all AT nodes
- upgrade first AT node
- join the other AT nodes
- dismount ISO
- stop transaction log monitoring
- manual verification
- re-enable backups
- update proxies
- after some usage delete snapshots
Currently I almost all steps are automated, typically with a script, but I still prefer to run the core steps (10 and 11) manually, so I am able to monitor what’s happening.
A very welcome feature, is the new ability of 2013.2 setup to retain previous settings, which made upgrading the proxy server a breeze.
Giulio
Comments
Nico : Hi Giulio, I just wanted to say that I appreciate your work. As a developer, I feel like that my VCS concerns are taken care of much more since your started with our company. Thanks! Nico